【搬运】VLM简短综述

视觉语言模型:基本认识
[TOC]
1. 定义和讨论范围
定义:“Vision Language Models or VLMs are AI models that use both images and textual data to perform tasks that fundamentally need both of them.” VLM 隶属于 AI 模型,这类 AI 模型使用图像或文本数据来执行本质上需要这两个模态的任务。
本文讨论的 VLM 特指于 “Our coverage will be exclusive to VLMs that generate text as output.” 也就是以文本(包括自然语言、数字、代码)为输出的 VLM 模型;而以图像为输出的模型此处不参与讨论。
2. 视觉语言模型适用任务
- Image Captioning: 生成描述图像的文字
- Dense Captioning: 生成描述图像的、包含图像中突出特点/特性的文字,相比于前者颗粒度更高
- Instance Detection: 在图片中使用 bounding box 来标注出检测到的物体
- Visual Question Answering (VQA): 针对图片进行文本模态的问与答
- Image Retrieval or Text to Image discovery: 从多张图像中找到最匹配输入文本描述的图像
- Zero Shot Image classification: 根据文本模态提供的类别信息直接对图像进行分类(无需额外训练)
- Synthetic data generation: 根据 VLM 的特性制造合成数据
3. 视觉语言模型发展历史
| 时间 | 2015 年前后 | 2020 年前后 | 2024年前后 |
|---|---|---|---|
| 内容 | 出现了两项工作:Show and Tell 用于生成图像描述,和Visual Question Answering 用于生成视觉问答。 | CLIP | ViT 和各种 LLM 的出现问世 |
| 意义 | 提出构建 VLM 的基本思路:通过调整视觉主干的图像嵌入使其与文本主干兼容,促进视觉和文本表征之间的有效沟通。 | 1. 使用互联网的图文数据;2. 使用对比学习。 | 二者成为了当前 VLM 的基本组成部分。 |
4. 视觉语言模型基本网络架构
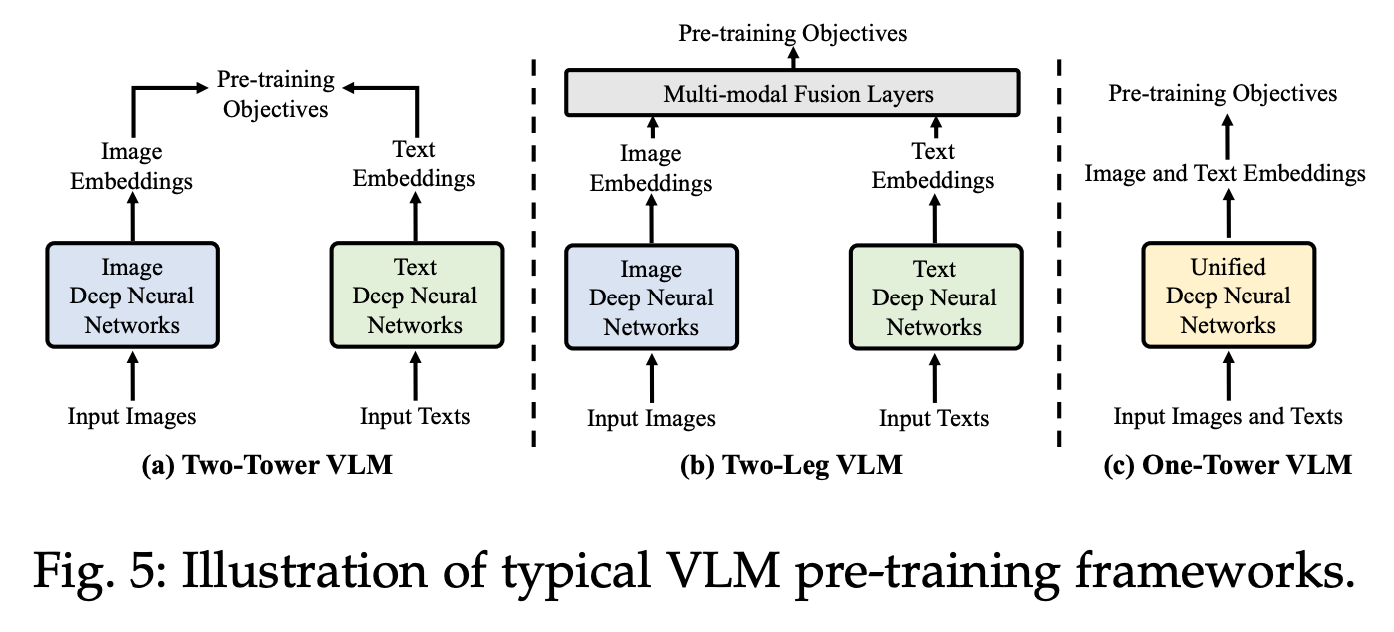
当前 VLM 的网络架构通常是以下三种:
- 双塔 VLM :视觉网络输出和文本网络输出的唯一连接位于整个 VLM 的最后一层。
- 双腿 VLM :单个 LLM 接受文本标记以及来自视觉编码器的标记。
- 统一/单塔 VLM :一个骨干同时处理视觉和文本输入。
5. 视觉语言模型的模态融合方式
5.1 Shallow/Early fusion 浅/早期融合
定义:视觉输入和语言输入之间的连接/结合发生在计算过程的早期,这意味着视觉输入在进入文本域之前只经历最少程度的转换,因此称为 “浅” 。
【做法一】确保视觉编码器(vision encoder)输出能够与 LLMs 的输入兼容,并且仅训练视觉编码器,同时保持大语言模型的参数冻结。该架构本质上是一个大语言模型(通常是 decoder-only 语言模型),它扩展出一个用于图像编码的分支。这种架构编码实现简单、易于理解,通常不需要编写新的网络层。这类架构的损失函数与普通的大语言模型相同,即关注下一个 token 的预测质量。“Frozen” 就是这类实现的一个示例。除了训练视觉编码器,该方法还采用了 prefix-tuning 技术:为所有视觉输入附加一个静态的前缀 token。这种设置使得视觉编码器可以根据 LLM 对前缀的响应进行自我调整。
【做法二】仅使用视觉编码器的问题在于,其输出很难确保与大语言模型(LLM)兼容,从而限制了视觉模型与语言模型的可选组合。更简单的做法是,在视觉网络和语言模型之间加入一个中间层(包括投影层 projector 和适配器 adapter ),使视觉编码器的输出能够适配 LLM 。通过在两者之间插入中间层,可以将任意视觉嵌入对齐到任意语言模型可以理解的形式。这种架构在灵活性上优于或等同于训练视觉编码器。这样可以选择同时冻结视觉网络和语言模型,同时由于适配器模块通常体积较小,也能加速训练过程。代表的 VLMs 有:
【简单中间层】Llava 系模型;
【简单中间层】Bunny: 有跨模态中间层 projector 的加持下,视觉输入可以使用多种编码器网络处理;文本输出可以使用多种语言模型产生;使用参数高效指令微调方法(LoRA)训练。
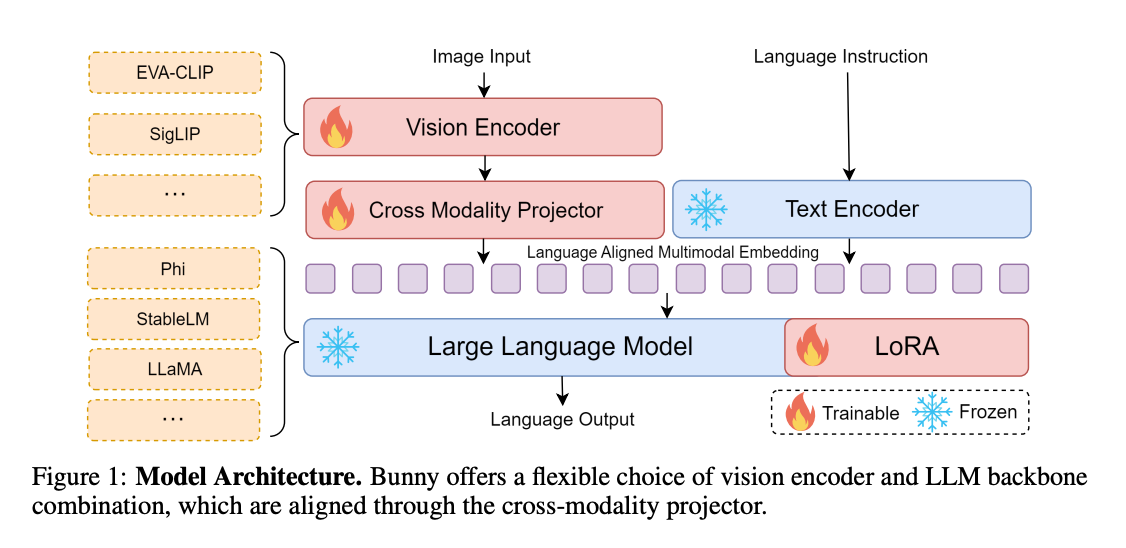
【简单中间层】MM1: 使用混合专家模型 MoE
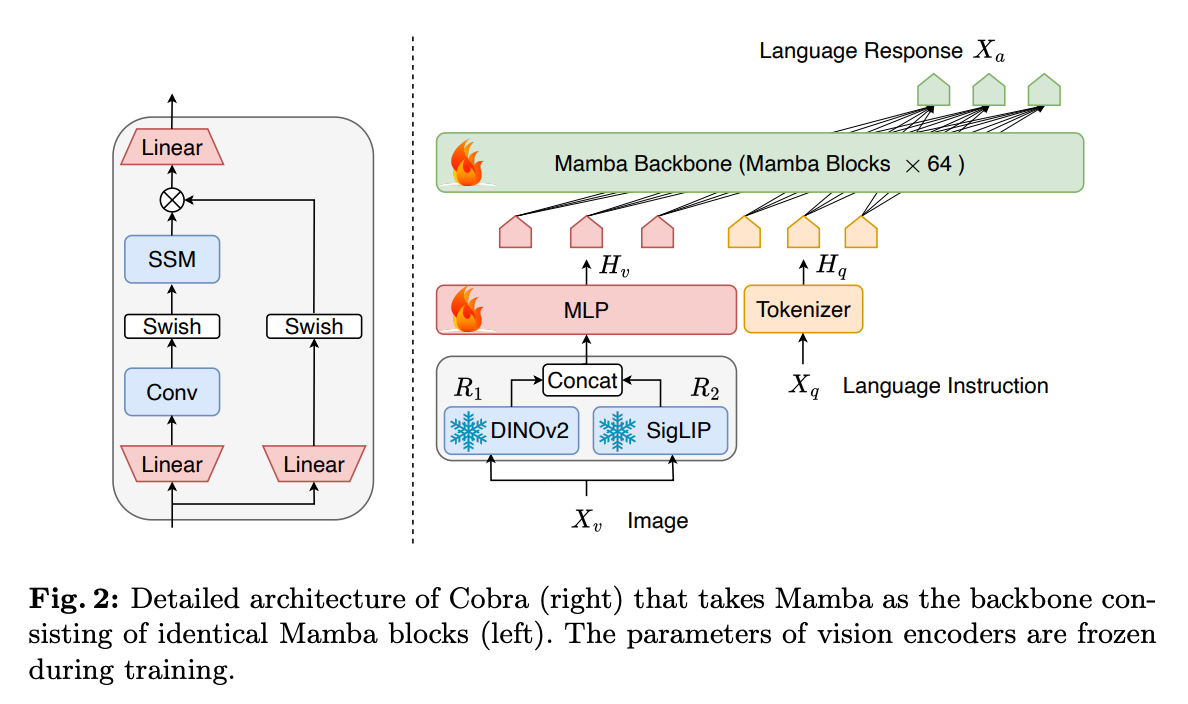
【简单中间层】Cobra: 使用 Mamba 架构取代传统 Transformer ,同时使用两个视觉编码器联合提取图像表征。
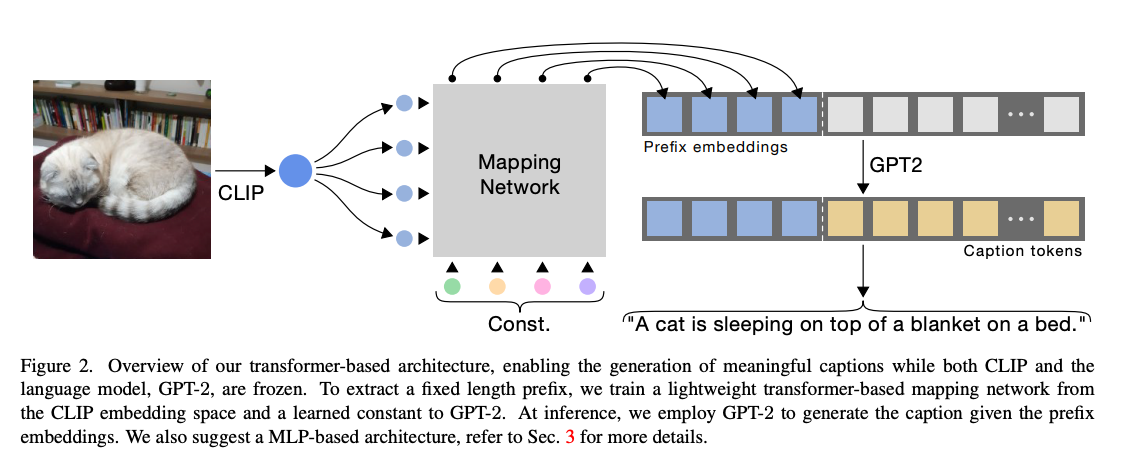
【复杂中间层】CLIP Cap: 视觉编码器采用 CLIP + 基于 Transformer 的映射网络,其中 Const. 是可学习常量。
【复杂中间层】BLIP-2: 使用 Q-Former 作为其中间层 projector ,以更有效地将图像内容与语言进行对齐和关联,实现更强的视觉语义对齐能力。
【复杂中间层】MobileVLMv2: 使用一种基于轻量级逐点卷积(point-wise convolution)的架构,并以 MobileLLama 作为小型语言模型(SLM)替代传统的大语言模型(LLM),重点提升推理速度。
【多中间层联合】BRAVE: 使用最多五个视觉编码器,并采用名为 MEQ-Former 的中间层,将所有视觉输入拼接为一个整体后再送入 VLM ,以实现多视角信息的融合与统一处理。
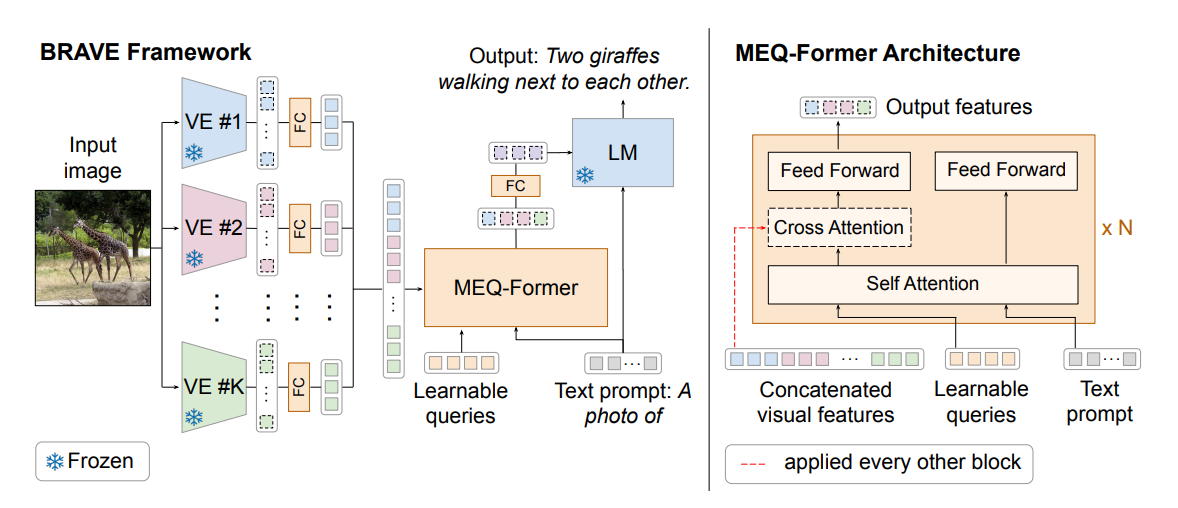
【多中间层联合】Honeybee: 使用两个专用的视觉编码器,分别称为 C-Abstractor 和 D-Abstractor。C-Abstractor 注重保持图像的局部性信息,而 D-Abstractor 则具备输出可变数量 token 的能力,从而实现更灵活和精细的视觉信息表达。
【多中间层联合】DeepSeek VL: 同样采用多个编码器,以保留图像中的高层语义信息和低层细节信息。然而,与其他方法不同的是,该模型还对 LLMs 进行联合训练,从而实现深度融合(deep fusion)。
5.2 Late Fusion 后期融合
这类架构中的视觉模型与文本模型是完全分离的。图像和文本的嵌入仅在损失计算阶段进行交互,而这种损失通常是对比损失(contrastive loss)。
- CLIP 就是这类架构的经典代表,其中图像和文本分别独立编码,通过对比损失进行匹配,从而共同优化各自的编码器。
- JINA CLIP 对传统 CLIP 架构进行了改进,不仅联合优化了 CLIP 损失(即 “图像—文本” 对比损失),还引入了 “文本—文本” 对比损失,其中只有语义相近的文本对才被视为相似。这其中的启示是:通过引入更多的目标函数,可以使多模态对齐更加精准。
- ColPali 是另一种典型的后期融合模型,专门用于文档检索。它与 CLIP 略有不同,ColPali 使用视觉编码器与 LLMs 结合来生成视觉嵌入,而文本嵌入则完全依赖于 LLMs 。
- ViTamin 训练了一个视觉主干网络,该网络将卷积块与 Transformer 块进行拼接融合,旨在兼具两者的优势,获得更优的视觉特征表示。
5.3 Deep Fusion 深度融合
这类架构通常在网络的深层对图像特征进行注意力处理,从而实现更丰富的跨模态知识传递。训练过程一般覆盖所有模态,虽然训练时间较长,但往往能带来更高的效率和准确性。有时,这些架构类似于 Two-Leg VLMs 且 LLM 参数处于非冻结状态。
CLIPPO 使用单个编码器同时处理视觉输入和文本输入。
Single-tower Transformer: 从头开始训练一个统一的 Transformer,使其能够同时支持多种 VLM 应用任务。
DINO: 在跨模态 Transformer 的基础上引入定位损失(localization loss),实现零样本目标检测,即能够预测训练集中未出现的类别。
KOSMOS-2: 将边界框(bounding boxes)作为输入和输出,与文本和图像的 token 一起处理,将目标检测能力直接内嵌到语言模型中。
Chameleon 通过使用量化器(quantizer)将图像原生地视作 token,从而构建出一种对文本与视觉模态均无偏向的通用架构。
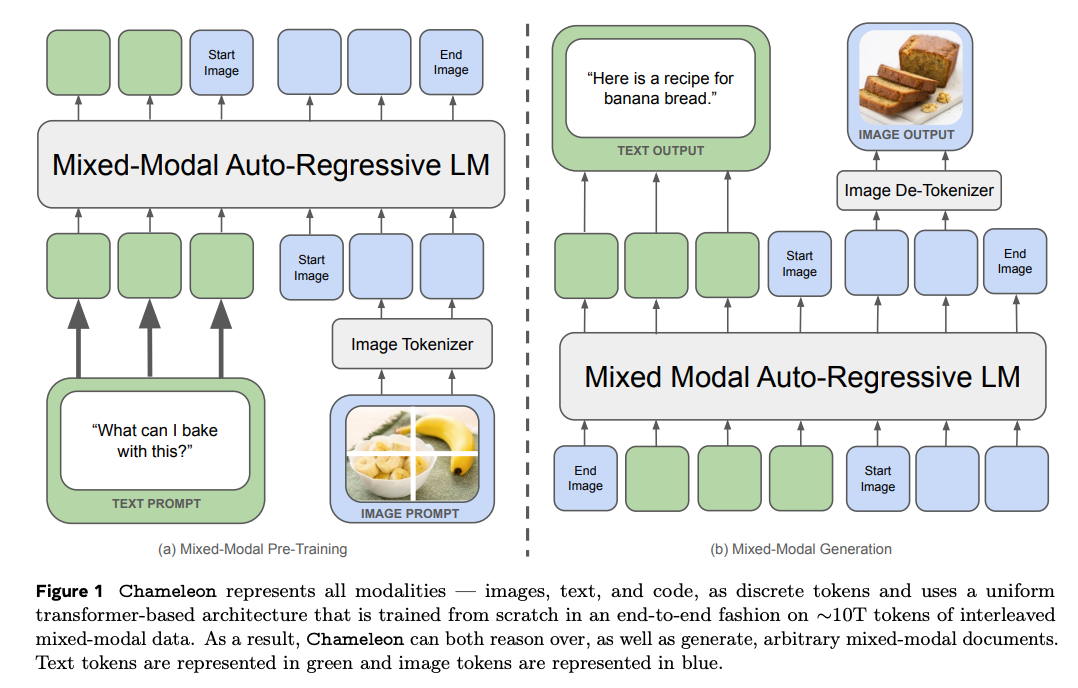
FIBER 通过动态开关交叉注意力模块(cross attention modules)来执行不同任务,实现灵活的功能切换。
BridgeTower 构建了一个独立的跨模态编码器,内置 “桥接层”(bridge-layer),能够在文本对视觉和视觉对文本的 token 之间进行交叉注意,捕捉更丰富的交互信息。
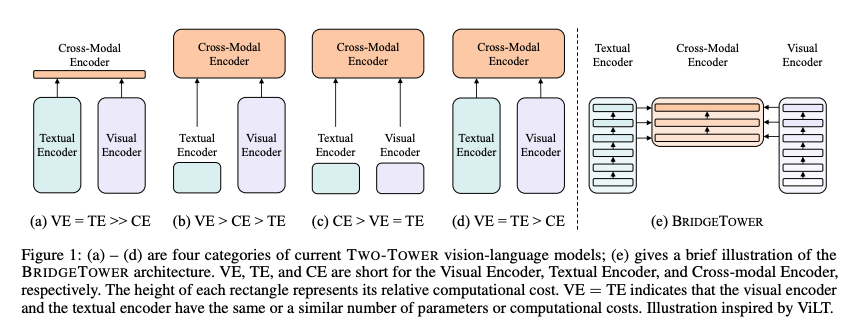
Flamingo 中,视觉 token 由改进版 ResNet 以及类似 DETR 的专用层 Perceiver Resampler 生成。随后,利用 Chinchilla LLM 作为冻结骨干,通过跨注意力将视觉 token 与语言 token 进行密集融合。
MoE-LLaVa 则采用 MoE 技术处理视觉和文本 token,训练分为两个阶段:首先仅训练前馈网络(FFNs),随后训练大语言模型(LLM)。
6. 视觉语言模型的训练过程
6.1 训练目标
6.1.1 Contrastive Loss 对比损失
这种方法旨在调整嵌入表征,使匹配对之间的距离最小化,而非匹配对之间的距离最大化。这种对比学习方法尤为有效,因为匹配对易于获取,而且还能指数级地增加可用于训练的负样本数量。CLIP 及其各种变体就是采用对比损失进行训练的经典范例,匹配关系发生在图像与文本的嵌入之间。InternVL、BLIP2 和 SigLIP 也是一些值得关注的相关模型。
SLIP 展示了在进行 CLIP 预训练之前,先对视觉编码器进行 “图像—图像” 的对比学习预训练,可以显著提升整体性能。Florence 对对比损失进行了改进,将图像标签和文本的哈希值引入其中,形成了一种称为 Unified-CL 的方法。ColPali 则结合了两种对比损失:一是 “图像—文本” 的对比损失,二是 “文本—文本” 的对比损失。
6.1.2 Generative Loss 生成式损失
这一类损失函数将 VLM 视为生成器,通常用于零样本任务和语言生成任务。
- 语言建模损失(Language Modeling Loss):这是在训练 VLM 进行下一个 token 预测时最常用的损失函数。Chameleon 对该损失进行了扩展,既用于预测文本 token,也用于预测图像 token。Florence2 则在所有任务中统一使用这种损失函数。
- 掩码语言建模(Masked Language Modeling, MLM):通过遮蔽部分文本 token 并让模型在上下文中进行预测,从而训练文本编码器。FIBER 就是使用这一方法的众多模型之一。
- 掩码图像建模(Masked Image Modeling, MIM):通过遮蔽输入图像中的一部分 token,让 Transformer 预测被遮蔽的信息,从而迫使模型在有限数据下学习。代表性方法包括:LayoutLM、SegCLIP 中使用的 MAE(Masked Autoencoder)、FLAVA 中采用的 BeiT 等。
- 掩码图像+文本建模(Masked Image+Text Modeling):顾名思义,这种方法在图像和文本两个模态中同时进行 token 的遮蔽,以最大限度地在有限数据下促进跨模态交互学习。FLAVA 就是这类方法的代表。
6.1.3 Niche Cross Modality Alignments 混合跨模态对齐
鉴于多模态任务的多样性,研究者常常可以设计出具有针对性的目标函数来实现更精细的模态对齐。例如:
- BLIP2 提出了图像引导的文本生成损失(Image-grounded Text Generation Loss),通过图像内容引导生成更贴合语义的文本。
- LayoutLM 使用了一种称为词块对齐(Word Patch Alignment)的机制,用于粗略识别文档中每个词所在的位置,从而将文本与图像中的文档结构进行对齐。
6.2 训练视觉语言模型的实践
预训练(Pre-training)
在这一阶段,通常仅训练 adapter 或者 projector ,并使用尽可能大量的数据(往往是数百万对 “图像—文本” 对)。目标是使图像编码器与文本解码器对齐,此阶段的重点在于数据量的规模。训练通常是无监督的,常用的损失函数包括 contrastive loss 或 next token prediction loss ,并通过调整输入文本 prompt,使语言模型能更好地理解图像上下文。
微调(Fine-tuning)
根据模型架构的不同,有些或全部模块(适配器、文本模型、视觉模型)从一开始就解冻参与训练。由于参数规模庞大,训练过程会非常缓慢。因此,此阶段使用的数据量通常仅是预训练阶段的一小部分,并且每条数据都需具备极高质量。
指令微调(Instruction Tuning)
这一阶段通常是训练流程中的第二步或第三步,旨在将模型调整为可用于聊天/问答等交互式任务。数据会被整理成 “指令—响应” 的格式,常通过现有 LLMs 将普通数据转化为指令形式。LLaVa 和 Vision-Flan 是典型例子。
使用 LoRA(Low-Rank Adaptation)
如前所述,微调过程中可能需要解冻 LLM 参数,而这是一项极其昂贵的操作。LoRA 提供了一种高效替代方案:通过在 LLM 各层之间插入小型的低秩适配层,能够在保持整体调整的同时,只训练 LLM 的一小部分参数,显著降低训练成本。
多分辨率输入(Multiple Resolutions)
在处理包含高密度信息的图像任务时(例如目标计数、拥挤人群识别或 OCR 中文字识别),VLMs 往往面临挑战。因此,支持多分辨率输入成为提高模型鲁棒性和适应能力的一项关键设计。
最简单的方式是将图像调整为多个不同的分辨率,并从每个分辨率中裁剪出所有子图(crops),然后将这些子图输入视觉编码器,并作为 token 喂入 LLM 。这一策略由 Scaling on Scales 提出,并被 Bunny 系列模型广泛采用,该系列在多项任务中表现出色。
LLaVA-UHD 则尝试寻找最优的图像切片(grid 划分)策略,在输入视觉编码器之前对图像进行合理划分。

InternLMXComposer2-4KHD 采用动态多分辨率策略,将图像在多个分辨率下裁剪得到的所有子图全部输入视觉编码器,从而更充分地捕捉图像中的细节信息。
6.3 训练数据集
| 数据集名称和年份 | 图文对数量 | 数据集描述 |
|---|---|---|
| WebLI (2022) | 12B | 基于 109 种语言的,网络爬取得到的,最大数据集之一。这不是公共数据集。 |
| LAION-5B (2022) | 5.5B | 基于互联网上收集得到的图像-文本对。最大的公开可用数据集之一,已被用来实现从头开始预训练 VLMs 。 |
| FLD-5B (2023) | 5B | 密集描述(dense captions)、OCR 信息以及定位信息(包括分割掩码和多边形轮廓)为构建一个统一的多任务学习模型提供了理想的基础。这种设计有助于模型在处理多种任务时实现知识共享,并显著提升其泛化能力。 |
| COYO (2022) | 700M | 另一个重要的数据集。通过图像级和文本级的筛选流程,过滤掉无信息量的图文对。 |
| LAION-COCO (2022) | 600M | 它是 LAION-5B 的一个子集,并使用合成手段生成的图像描述,因为原始的 alt-text 往往并不准确。 |
| Obelics (2023) | 141M | 该数据集采用对话格式,即图像与文本组成的多轮对话,非常适用于指令预训练和指令微调任务。 |
| MMC4 (Interleaved) (2023) | 101M | 同样是聊天格式,该数据集还使用线性分配算法(linear assignment algorithm),借助 CLIP 特征将图像合理地插入到较长的文本中,增强图文之间的上下文关联性。 |
| Yahoo Flickr Creative Commons 100 Million (YFCC100M) (2016) | 100M | 这是最早期的大规模多模态数据集之一。 |
| Wikipedia-based Image Text (2021) | 37M | 其独特之处在于将图像与百科式知识关联起来。 |
| Conceptual Captions (CC12M) (2021) | 12M | 与多数只关注现实世界物体或事件的数据集不同,它涵盖了更大范围、更具多样性的概念。 |
| Red Caps (2021) | 12M | 该数据集采集自 Reddit,因此其 captions 反映了真实世界中用户生成的内容,涵盖多种类别,具有更高的真实性与多样性,相比标准数据集更加贴近自然语言使用方式。 |
| Visual Genome (2017) | 5.4M | 该数据集还包含丰富的标注信息,包括物体检测、物体之间的关系、以及场景中物体的属性,使其非常适合用于场景理解与 dense captioning 等任务。 |
| Conceptual Captions (CC3M) (2018) | 3.3M | 该数据集更适合微调。 |
| Bunny-pretrain-LAION-2M (2024) | 2M | 该数据集强度 “视觉—文本” 的对齐。 |
| ShareGPT4V-PT (2024) | 1.2M | 该数据集源自 ShareGPT 平台,其 captions 由一个模型生成,而该模型本身是基于 GPT-4V 生成的描述数据进行训练的。这使得数据集中的文本具有较高的语言质量与视觉理解能力,适用于多模态模型的高质量指令微调和评估。 |
| SBU Caption (2011) | 1M | 该数据集采集自 Flickr ,适用于研究日常场景中图像与文本之间的自然对应关系。它以休闲、生活化的图像为主,能够支持模型在处理非专业、真实用户生成内容时的表现与泛化能力。 |
| COCO Caption (2016) | 1M | 每张图片均有 5 个独立的人类进行描述。 |
| Localized Narratives (2020) | 870k | 该数据集包含定位到具体物体的描述信息,非常适合用于图像定位(image grounding)等任务。 |
| ALLaVA-Caption-4V (2024) | 715k | 该数据集的图像描述由 GPT-4V 生成,主要聚焦于图像描述和视觉推理任务。 |
| LLava-1.5-PT (2024) | 558k | 另一个通过调用 GPT-4 生成的数据集,重点在于提供高质量的提示 prompts ,以支持视觉推理和密集描述任务。 |
| DocVQA (2021) | 50k | 这是一个基于文档的视觉问答数据集,问题主要聚焦于文档内容,因而在金融、法律或行政等领域的信息抽取任务中具有重要价值。 |
7. 视觉语言模型评估
MMMU(Massive Multi-discipline Multimodal Understanding and Reasoning)
MMMU 基准测试是当前评估 VLMs 最受欢迎的基准之一。该基准涵盖多个学科领域,旨在测试 VLMs 的泛化能力,确保优秀的 VLMs 能够跨领域表现出稳定性能。该基准主要评估三项核心能力:感知能力(perception)、知识理解(knowledge)和推理能力(reasoning)。评估采用零样本(zero-shot)设定,要求模型在不进行微调或少样本提示的情况下直接生成准确答案,真正考验其泛化和理解能力。MMMU-PRO 是该基准的增强版本,在原有基础上引入了更具挑战性的问题,并剔除了一些仅凭文本输入就能轻松解答的数据点,从而提升了整体评估的难度与区分度。
MME
MME 数据集高度注重质量,所有图像均为精心挑选并人工标注,并确保这些图像和问题在互联网上完全不可获取,以避免 VLMs 在训练阶段意外接触这些样本,从而保障评估的公正性与准确性。该基准包含 14 个子任务,每个任务约含 50 张图像,每个任务的回答均为是/否(Yes/No)形式。一些典型任务包括:物体是否存在、对知名人物或物品的感知、文本翻译等。每张图像都配有两道问题:一道是正向问题,期望模型回答 “YES” ;一道反向问题,期望模型回答 “NO” 。每个子任务都构成一个独立的评估基准。除此之外,还有两个子聚合基准:认知子基准(Cognition Benchmark):聚合所有推理类子任务的准确率;感知子基准(Perception Benchmark):聚合所有感知类子任务的准确率。最终的总体基准得分为上述所有子任务基准的总和,用于全面衡量模型在认知与感知方面的综合能力。

MMStar
该数据集是从 6 个 VQA 数据集中精挑细选出的一个高质量子集,经过严格筛选以确保以下几点:(1)无法仅凭 LLMs 的文本模态知识作答,图像信息是不可或缺的。(2)问题本身不包含答案,确保图像在回答过程中不是可有可无的。(3)问题与答案的文本内容未直接出现在 LLMs 的训练语料中,防止模型通过记忆作答。与 MME 类似,该数据集强调的是质量而非数量,适用于更严谨和真实的多模态模型评估。
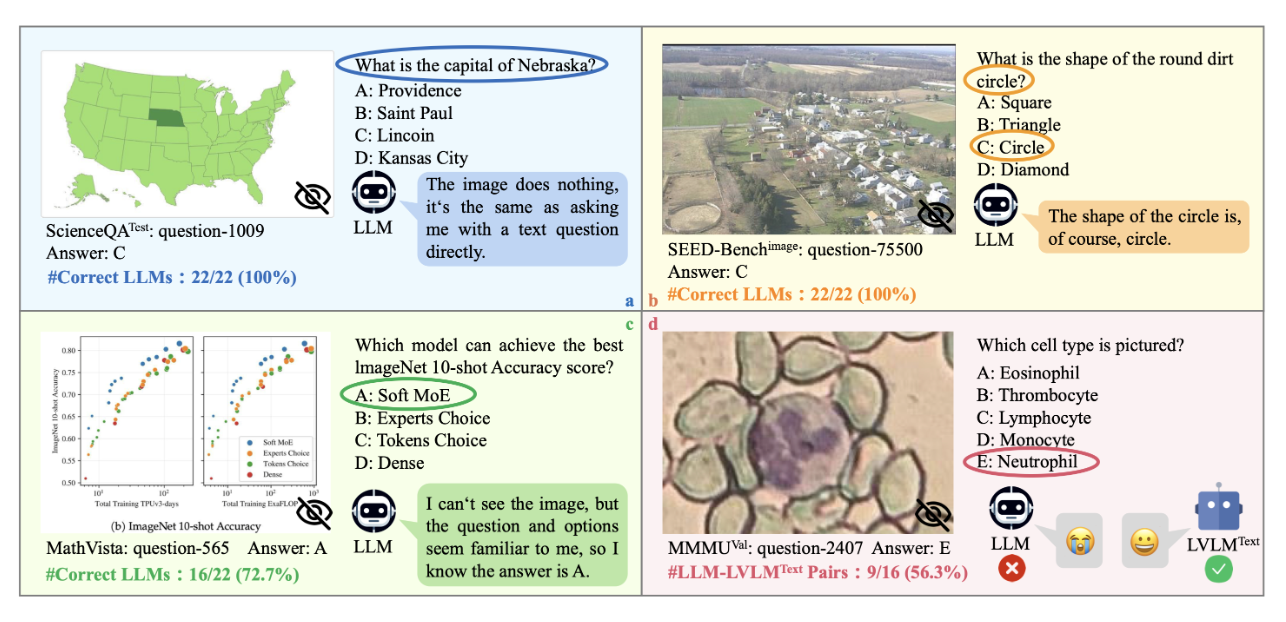
Math-Vista
该基准测试数据集从 31 个不同来源收集并精心整理而成,专注于数学相关问题,涵盖了多种推理类型、任务形式、年级水平和语境场景。其多样性使其成为评估模型在数学理解与推理能力方面的重要工具。
MathVerse
MathVerse 是一个与上述数学基准类似但有所不同的数据集,主要聚焦于更具体的数学领域,如二维几何、三维几何以及解析函数等内容。该数据集更强调视觉与空间推理能力,适用于评估模型在几何与函数理解方面的多模态能力。
AI2D
这是一个高度专注于科学图示的数据集,旨在评估 VLMs 对高级科学概念的理解能力。模型不仅需要解析图中的各个元素,还要理解它们之间的相对位置关系、箭头指向关系,以及每个组成部分所附带的文本信息。该数据集包含 5000 张小学科学图示,配有超过 150,000 条丰富注释、对应的句法解析(syntactic parses),以及 15000 多个多项选择题,为模型提供了全面的科学图示理解和推理评估基准。

ScienceQA
这是另一个面向特定领域的数据集,专门用于评估模型在思维链范式下的表现。它不仅要求模型选择正确的多项选择题答案,还需生成详尽的推理解释,以验证其推理深度和逻辑连贯性。此外,该数据集还测试模型的对话式交互能力,通过输入多段文本和多张图像,评估其在复杂上下文中的理解与应答能力,是对多模态模型综合语言推理与多轮对话处理能力的有力检验。
MM-Vet v2
这是最受欢迎、同时也是体量最小的基准测试之一。该数据集通过评估 “单图—单文本” 和类聊天场景下的多种任务,全面考察模型的以下能力:识别能力、常识与知识理解、空间感知、语言生成、光学字符识别和数学推理能力。在该基准上,InternVL 是开源模型中表现最优秀的之一,再次展现其在多模态理解方面的强大能力。
VisDial
VisDial 一个源自 COCO 数据集的多模态数据集,旨在评估 VLM 聊天机器人在面对一系列图像与文本输入后,对后续问题的回答能力。它更关注于对上下文图文交互的理解与连续对话能力。
LLaVA-NeXT-Interleave
LLaVA-NeXT-Interleave 一个评估模型在多图输入情境下表现的基准测试。它整合了 9 个新数据集和 13 个已有数据集(包括 Muir-Bench 和 ReMI),全面考察模型在处理多张图像时的整合理解能力、跨图推理能力与一致性判断能力。
SEED
具有图像和视频模态的多项选择题。
VQA
最早的数据集之一,覆盖了广泛的日常场景。
GQA
GQA 是一个专注于组合式问答的数据集,其问题通常涉及图像中多个物体之间的关系与属性组合。例如,问题可能要求模型理解 “左边的红色物体是否在蓝色桌子上?” 这类需要多层次推理的问题。GQA 强调模型的逻辑推理能力、结构化理解以及对复杂视觉语义的掌握。
VisWiz
VisWiz 是一个由盲人用户生成的数据集。每位盲人拍摄一张图片(啊??????),并针对该图片录制一段口述提问,随后通过众包方式为每个视觉问题收集了约 10 个答案。该数据集反映了真实用户在视觉辅助场景下的需求,特别适用于评估模型在辅助盲人理解视觉内容方面的能力。
POPE
POPE 是一个有趣的数据集,展示了如何通过简单的构建模块创造复杂的测试场景。它的问题形式主要是判断图像中某些物体的存在或不存在,首先利用目标检测模型识别图像中的物体作为 “存在” 样本,再通过否定方式生成 “缺失” 或 “不存在” 的样本集。该数据集不仅用于考察模型对物体存在性的理解能力,还被用于检测 VLMs 是否出现 “幻觉” 现象,即模型对不存在物体的错误预测。
8. 训练 VLMs 需要关注的问题
8.1 明确任务需求
- 明确模型用途:只做 VQA ?还是需要图像检索、grounding 等功能?
- 交互方式:单张图片输入还是支持对话式交互?
- 性能要求:是否实时响应?客户端能否等待?
- 任务不同,模型大小和架构选择不同。
8.2 数据与模型选择
- 先用现有 SOTA 做 zero-shot 或 one-shot 测试,验证数据适配性。
- 数据复杂或专业时,评估数据量,决定是从头训练还是微调已有模型。
- 数据量不足时,考虑用现有 LLMs(GPT、Gemini、Claude等)生成高质量合成数据扩充。
8.3 损失函数设计
- 设计多目标损失函数确保任务被充分表达,借鉴 CLIP 变体、LayoutLM、BLIP-2 等多损失训练方法。
- 好的损失设计可以显著提升模型效果。
8.4 评估与业务指标
- 选择适合的公开 benchmark 进行评测。
- 制定符合实际业务需求的指标,不能只依赖损失或 benchmark 成绩。
- 业务指标才是真正决定模型是否可用的标准。
8.5 微调策略
- 第一阶段只训练 adapter 模块。
- 第二阶段用 LoRA 技术联合训练视觉编码器和语言模型。
- 保证数据质量,避免劣质样本拖累训练。
8.6 从零训练策略
- 选择适合领域的骨干网络。
- 采用多分辨率技术捕捉图像多层次细节。
- 使用多个视觉编码器融合信息。
- 对复杂数据,采用 MoE 策略训练语言模型。
8.7 高级实践
- 先训练超大模型(50亿参数以上),再用知识蒸馏(distillation)缩小模型。
- 试验多种架构组合,形成 “模型家族” ,选择最优组合。