QwenVL系列多模态模型学习笔记-第2篇
第二代 Qwen2-VL 2024.09-2024.10
参考网页:
- 引入原生动态分辨率(Naive Dynamic Resolution, NDR)机制 —— 实现了对任意分辨率图像/视频的灵活处理。
- 设计多模态旋转位置嵌入(Multimodal Rotary Position Embedding, M-RoPE) —— 实现更有效的跨模态信息融合;还增强了长序列任务中的推理表现,在视频内容理解中尤为突出。
- 统一的图像和视频理解框架 —— 图像被处理为两个相同帧,保持与视频处理的一致性;使用 3D tubes 替代 2D patches 处理方式确保模型对多模态任务的全面适配。
更强的复杂推理和决策的能力,可根据视觉环境和文字指令进行自动操作手机、机器人等设备。
支持除英语和中文外,也支持大多数欧洲语言、日语、韩语、阿拉伯语、越南语等多语言。
显著性能提升 —— 在多个权威基准数据集上实现了新 SoTA 。
模型结构
通常一个多模态 “视觉—语言” 模型包含三个结构:语言模型、视觉编码器和 “视觉—语言” 适配器。
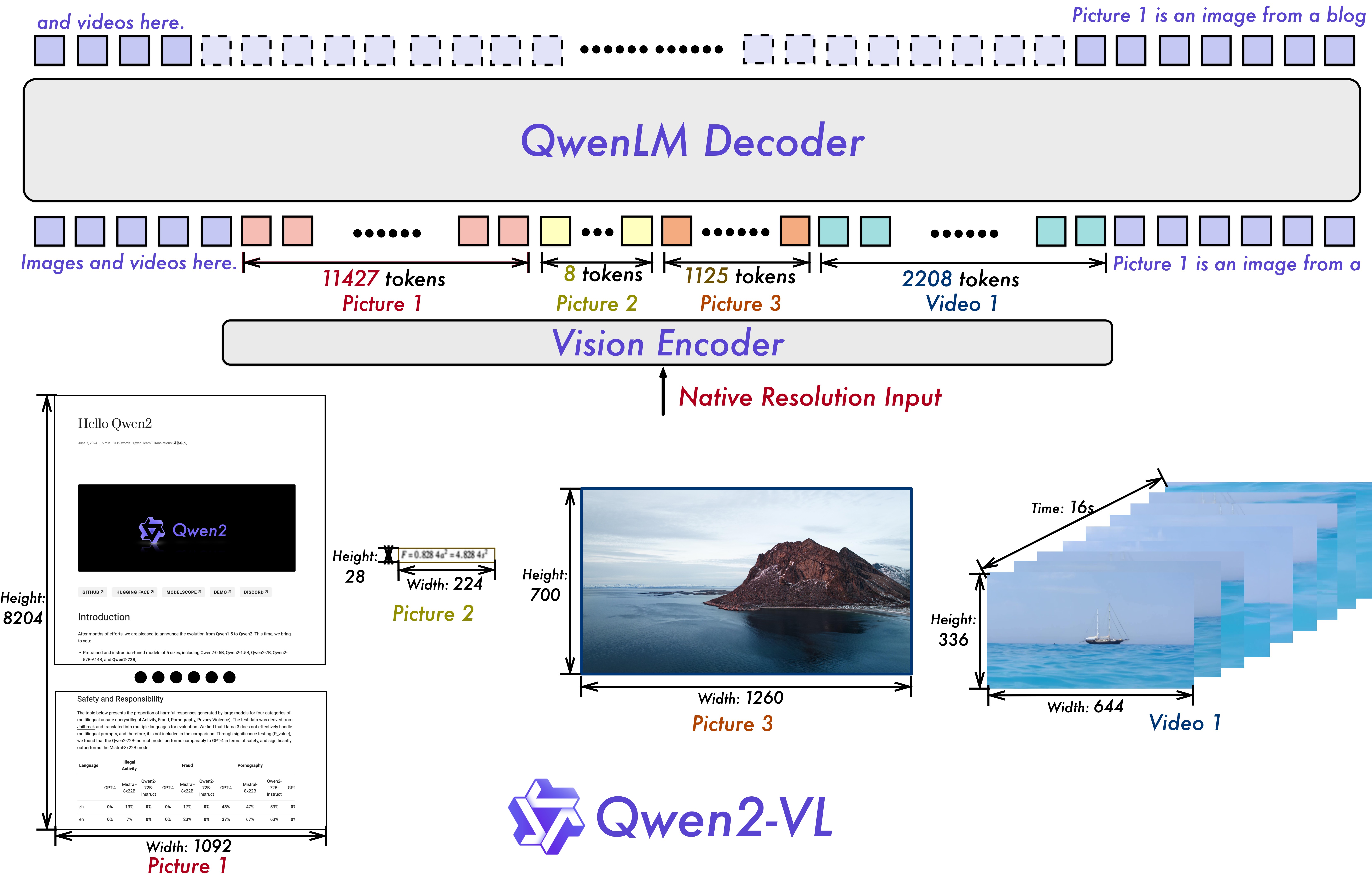
视觉编码器:
Qwen2VisionTransformerPretrainedModel图像和视频帧经过基于 ViT 的视觉编码器后,生成一系列视觉特征 token 。取代传统绝对位置编码,模型通过二维 RoPE 嵌入捕捉图像中像素空间分布信息。为了降低计算复杂度,视觉特征通过一个简单的 MLP 层进一步压缩,将邻近的 2x2 视觉 token 合并为一个 token ,同时在 token 序列的起始和结尾处分别添加
<|vision_start|>和<|vision_end|>标记。语言模型:
Qwen2VLModel使用 Qwen2-LM ,Qwen2 系列语言模型都是基于 Transformer 的解码器结构。视觉特征 tokens 和文本 tokens 通过统一的输入序列被送入 Qwen2 系列语言模型中,进行多模态信息的融合和处理。
没有明显的 “视觉—语言” 适配器部分,视觉编码向量没有经过太多的处理直接进入了语言模型。
精致的 “视觉—语言” 适配器似乎正变得没那么重要,早在多模态模型诞生之初就有 ViLT 这样的将图片直接用线性层投影作为 Transformer 输入的架构,现在也有一些轻量的多模态模型用 MLP 对图片进行处理,直接删除了视觉编码器,可见多模态信息的融合不一定需要太复杂的结构。
多模态旋转位置嵌入(M-RoPE)
M-RoPE 在视觉和文本 token 之间建立精确的位置信息关联。特别是在视频任务中, M-RoPE 能够捕捉时间维度的动态变化,使模型能够处理长时间的视频内容。
对于文本,位置编码与传统的 1D-RoPE 一致,采用一维序列编号来标记词位位置。
对于图像,M-RoPE 通过二维位置编码为每个视觉 token 分配宽度和高度的位置标识,以准确表示图像中的空间结构。同时,图像中的时间维度编码值保持固定,因为静态图像没有时间变化。
对于视频,M-RoPE 进一步扩展,通过对每一帧引入递增的时间位置标识,并结合图像的宽度和高度位置编码,使模型能够理解视频帧的动态时间序列信息。
模型输入和输出
图像输入:模型根据输入图像的分辨率,动态调整视觉 token 的数量,而不是将所有图像固定调整到同一尺寸。
视频输入:对于视频数据,为了一致性,每个图像被视为两个相同的帧。为了平衡长视频处理的计算需求和整体训练效率,动态调整每个视频帧的分辨率,将每个视频的令牌总数限制在 16384 个,并利用动态分辨率机制压缩多帧内容为适合语言模型处理的视觉 token 序列。
模型输出:
- 视觉问答(VQA):回答与图像或视频相关的问题。
- 文档理解与 OCR :识别和解析复杂文档中的文本信息。
- 视频内容分析:对长视频内容进行总结、生成对话内容或回答基于视频的问题。
- 代理能力:支持设备操作,如根据屏幕截图导航手机界面。
模型训练过程
第一阶段:ViT 训练,冻结语言模型参数
使用大量的 “图像—文本” 对数据集来增强大语言模型(LLM)中的语义理解,让模型学会图像和文本之间的关系,以及通过 OCR 在图像中识别文本内容和图像分类任务。
在这一阶段,Qwen2-VL 大约使用 6000 亿个标记的语料库预训练。LLM 部分使用 Qwen2 的参数进行初始化,而 ViT 部分则使用从 DFN 派生的 ViT 进行初始化,同时将固定位置编码替换为 RoPE-2D 。
DFN 即 Data Filtering Network,是一个小型的、专门用于 “筛数据” 的神经网络。它通常会接收图像—文本对,并预测其质量评分,高分样本被保留用于训练大型预训练模型。它本身不直接生成训练模型,而是在 “构建训练集” 的中间环节发挥作用。
第二阶段:解冻 ViT 和语言模型进行全参数训练
解冻所有参数,并使用更广泛的数据进行训练,以实现更全面的学习。这个阶段引入了额外的 8000 亿个图像相关数据的标记,通过引入更多的混合 “图像—文本” 内容(混合图文内容、视觉问答数据集、多任务数据集和纯文本数据),以促进视觉和文本信息之间更细微的理解。仅对文本 tokens 提供监督。
第三阶段:LLM 的微调
使用 ChatML 格式构建指令跟随数据。冻结 ViT 参数,使用指令数据集(纯文本对话和多模态混合数据集:图像问答、文档解析、多图比较、视频理解、视频流对话和基于代理的交互)对 LLM 进行专门的微调。